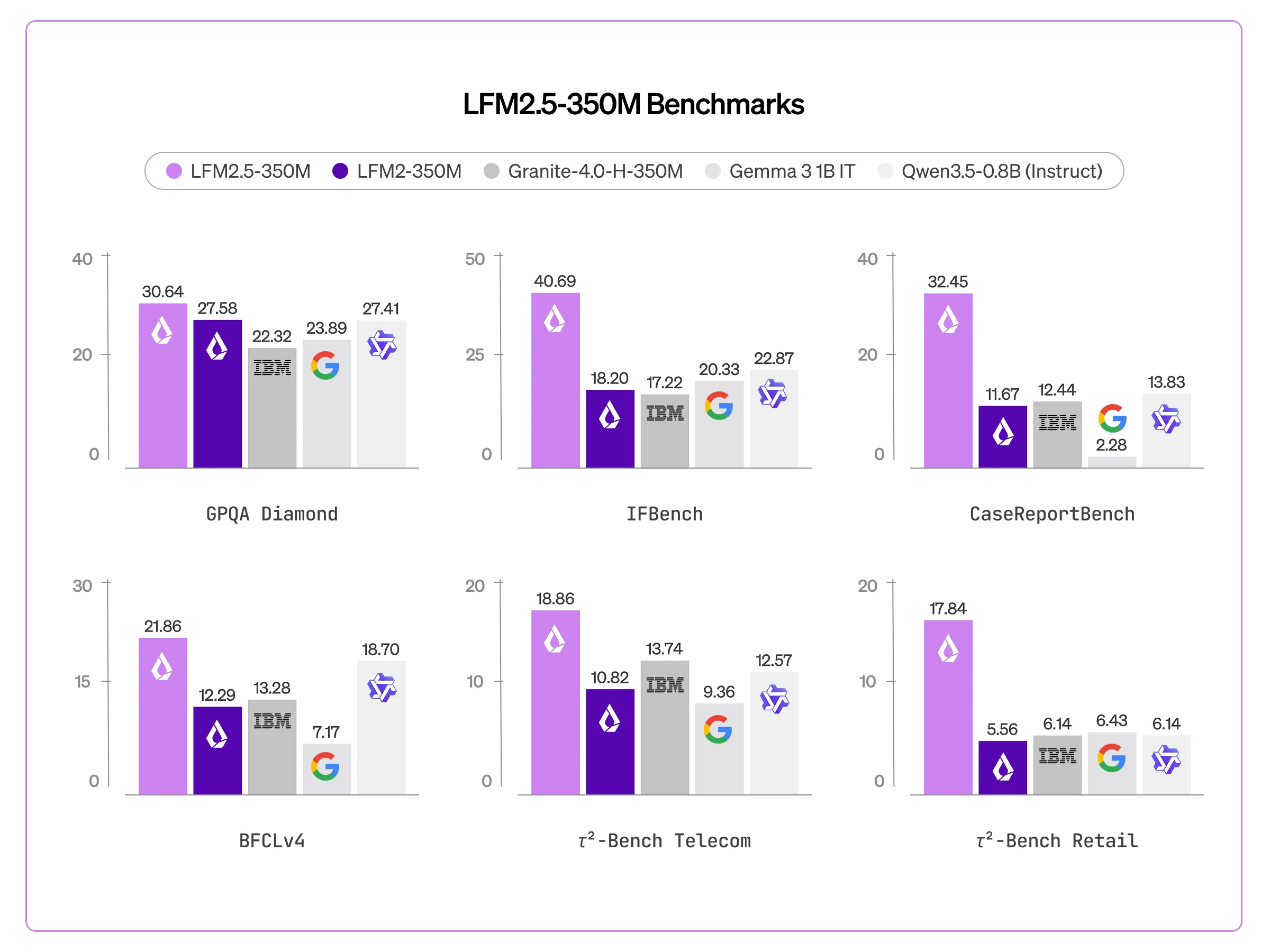
For years, the prevailing religion of artificial intelligence research has been scale. More parameters, more compute, more data — the assumption being that raw size is the closest proxy we have for machine intelligence. Liquid AI's latest release quietly but forcefully pushes back on that orthodoxy.
The company has released LFM2.5-350M, a language model with just 350 million parameters that was trained on 28 trillion tokens, up from an earlier checkpoint trained on 10 trillion. Paired with large-scale reinforcement learning, the result is a model that punches well above its weight class — a compact system that the company is positioning not as a stepping stone to something bigger, but as a deliberate architectural argument about how intelligence should be built.
The conventional framing in AI development treats parameter count as the headline number. GPT-4 is estimated to have over a trillion parameters across its mixture-of-experts architecture. Meta's LLaMA 3.1 405B speaks for itself in the name. In that context, 350 million parameters sounds almost quaint. But the more interesting number in Liquid AI's release is 28 trillion tokens of training data — a figure that represents an unusually high ratio of data to model size.
This matters because of what researchers sometimes call the "Chinchilla optimal" framework, a concept introduced by DeepMind in 2022 suggesting that most large models are actually undertrained relative to their size. The implication was that you could get equivalent performance from a smaller model trained on far more data. Liquid AI appears to be taking that principle seriously and extending it further, combining data volume with reinforcement learning to squeeze more capability out of fewer parameters.
Reinforcement learning at scale is doing meaningful work here too. Rather than simply predicting the next token, reinforcement learning allows a model to optimize toward outcomes — rewarding useful, accurate, or coherent responses and penalizing failures. When applied at scale to an already data-rich model, it can sharpen reasoning and instruction-following in ways that raw pretraining alone cannot. The combination of extended pretraining and RL fine-tuning is becoming a signature move for labs trying to compete without matching the compute budgets of OpenAI or Google.
The strategic logic behind a 350M parameter model is not hard to read. Edge deployment — running AI on devices rather than in data centers — is one of the fastest-growing segments of the industry. Smartphones, embedded systems, medical devices, and industrial sensors all represent environments where a model that requires 80GB of GPU memory simply cannot operate. A well-trained compact model that fits in a fraction of that space, while still delivering coherent and useful outputs, is genuinely valuable in ways that the benchmark leaderboards don't always capture.
There's also a cost argument that compounds over time. Inference — the act of running a model to generate a response — is where most of the real-world compute expense lives. A smaller model costs less per query, scales more cheaply, and produces a lower carbon footprint per interaction. As AI gets embedded into more routine workflows, those per-query costs accumulate into serious infrastructure expenses. Efficiency isn't just an engineering virtue; it's a business model.
The second-order consequence worth watching here is what happens to the broader research culture if compact, heavily-trained models start matching or exceeding the practical performance of much larger ones. The current investment cycle in AI is partly justified by the assumption that scale remains the dominant variable. If that assumption weakens — if the community broadly accepts that training duration, data quality, and reinforcement learning can substitute for raw parameter count — the economics of frontier AI development shift considerably. Smaller labs with less compute but smarter training regimes become more competitive. The moat that hyperscalers have built around sheer infrastructure starts to look less impenetrable.
Liquid AI is not the only lab working in this direction. Microsoft's Phi series, Google's Gemma models, and Apple's on-device research all reflect a growing institutional interest in doing more with less. But the specific combination of 28 trillion training tokens and scaled reinforcement learning in a sub-billion parameter model is a notable data point in an argument that the field is only beginning to have seriously.
The question that will define the next phase of this debate is not whether small models can be made smarter, but whether the benchmarks and evaluation frameworks used to judge AI systems are even asking the right questions. If the metrics were designed in an era when size was the variable, they may be poorly equipped to capture what efficiency-first architectures actually deliver in the real world.
References
- Hoffmann et al. (2022) — Training Compute-Optimal Large Language Models
- Touvron et al. (2023) — LLaMA 2: Open Foundation and Fine-Tuned Chat Models
- Abdin et al. (2024) — Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
- Ouyang et al. (2022) — Training language models to follow instructions with human feedback
Discussion (0)
Be the first to comment.
Leave a comment